00:00:00
查找 原创
下图从宏观上展示了查找算法的分类体系,帮助您建立清晰的知识结构:
一、查找的基本概念
- 查找表:由的数据元素(或记录)。
- 关键字:数据元素中,用于标识该数据元素。
- 主关键字:。
- 静态查找:操作,集合内的。对应上图的“基于线性表查找”。
- 动态查找:在过程中,或。查找表本身是动态变化的。对应上图的“基于树结构查找”。
- 平均查找长度(ASL):。为。
- 计算公式:
- :查找第 个记录的概率(通常)。
- :找到第 个记录。
二、静态查找(线性表的查找)
2.1 顺序查找
- 方法:从表的一端开始,将记录的关键字与给定值进行。
- 适用性:适用于和的线性表。
- 平均查找长度ASL:
- 成功情况:
- 失败情况:
- 示例:在数组
[5, 3, 8, 1, 2]中查找8。- 步骤:
5(不等于8) ->3(不等于8) ->8(等于8,查找成功)。
- 步骤:
- 性能指标:
- 时间复杂度:
- : 目标在为 。
- : 目标在为 。
- 。
- 空间复杂度:。无需额外空间。
- 稳定性:。因为是从前向后顺序比较,不会改变相同关键字的相对位置(但查找算法本身通常不涉及数据移动,这里的“稳定”指查找过程本身)。
- 时间复杂度:
- 特点:
- 对(顺序或链式均可)。
- 对元素。
- 算法简单,但效率低下()。
- 哨兵技巧:在表头设置“哨兵”元素,可以避免每次循环都需要检查数组是否越界,能略微减少比较次数。
2.2 折半查找(二分查找) - 重中之重
- 方法:要求线性表必须采用,且表中元素按关键字,,根据比较结果将查找范围缩小一半,。
- 步骤:
- 设置一个区间
[low, high],初始low=1,high=n。 - 取中间位置
mid = ⌊(low + high) / 2⌋。 - 比较给定值
key与mid位置的值:- 若相等,则查找成功。
- 若
key较小,则high = mid - 1,在左半区继续查找。 - 若
key较大,则low = mid + 1,在右半区继续查找。
- 重复步骤2-3,直到
low > high(查找失败)。
- 设置一个区间
- 示例:在有序数组
[1, 3, 5, 8, 12, 16]中查找12。low=0, high=5 -> mid=(0+5)/2=2 -> arr[2]=5 < 12 -> low=mid+1=3low=3, high=5 -> mid=(3+5)/2=4 -> arr[4]=12 == 12(查找成功)
- 性能指标:
- 时间复杂度:。。
- 空间复杂度:。
- 稳定性:。在遇到相同关键字时,会继续向一侧收缩,最终定位到某个特定元素。
- 特点:
- 要求:结构,且。
- 查找过程可用判定树来描述,其树高最大为 。
- 判定树:二分查找的过程可以用一棵来描述,树中每个结点对应一个中间位置。。
- 平均查找长度ASL:
- 当 足够大时:。
- 适用场景
- 折半查找适用于,且又的情况。
- 考点:
- 给定一个有序序列,手工模拟二分查找的过程,写出比较的中间位置
mid。 - 计算给定序列的二分查找判定树,并计算成功和不成功情况下的ASL。
- 给定一个有序序列,手工模拟二分查找的过程,写出比较的中间位置
2.3 分块查找(索引顺序查找)
- 方法:结合顺序查找与二分查找的优点,将数据分为若干块
- 块内元素可以,但(即第
i块的所有关键字均大于第i-1块的最大关键字)。 - 再建立一个(存储每块的最大值和起始地址),定位目标所在块,再在块内查找。
- 块内元素可以,但(即第
- 示例:表
[5, 3, 8, 1, 12, 10, 15, 18],分成三块:[5,3,8,1],[12,10],[15,18]。索引表为[8, 0],[12, 4],[18, 6]。查找10:- 确定块:
10 > 8 && 10 <= 12-> 在第二块。 - 在第二块
[12,10]内顺序查找,找到10。
- 确定块:
- 性能指标:
- 时间复杂度:
- 平均: 注1
- 最坏:
- 空间复杂度:。需要额外空间存储索引表。
- 稳定性:。取决于块内查找所用的方法(通常是顺序查找,故稳定)。
- 时间复杂度:
- 特点:,适合且。
- 平均查找长度ASL:
- 其平均查找长度不仅与表长 有关,而且与每一块的记录数 有关。
- 当 取 时, 取最小值 时的查找效率较顺序查找要好得多,但远不及折半查找。
三、动态查找(树表的查找)
3.1 二叉排序树(BST)
- 定义:一棵,或者:
- 若左子树不空,则的值。
- 若右子树不空,则的值。
- 左、右子树也分别为二叉排序树。
- 查找:从,与当前结点比较,。
- 插入:查找时,位置即为查找路径上。
- 删除:软考难点。分三种情况:
- 删除叶子结点:直接删除。
- 删除只有一棵子树的结点:用其子树顶替。
- 删除有两棵子树的结点:用其 顶替,。
- 示例:在BST中查找
12。8 / \ 3 10 / \ \ 1 6 14 / 12- 步骤:
8->10->14->12(查找成功)。
- 步骤:
- 性能指标:
- 时间复杂度:
- 平均情况: (树比较平衡时)。
- 最坏情况: (树退化为单支链表,如插入序列为
1,3,6,8,10,14,12)。
- 空间复杂度:。存储n个节点。
- 稳定性:。插入顺序不同,生成的树结构不同。查找过程不影响结构,但树本身不保持相同关键字记录的原始插入顺序。
- 时间复杂度:
- 特点:
- 是动态查找表,支持高效的插入和删除操作。
- 性能取决于树的形态,可能退化为 。
备注
从二叉排序树的定义可知,中序遍历二叉排序树可得到一个关键字。这也说明, 一个可以,构造二叉排序树的过程就是 对无序序列进行排序的过程。
3.2 平衡二叉树(AVL)
- 目的:解决BST可能的问题,提高查找效率。
- 定义:树上。
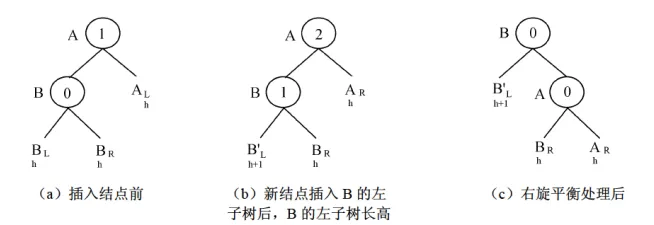
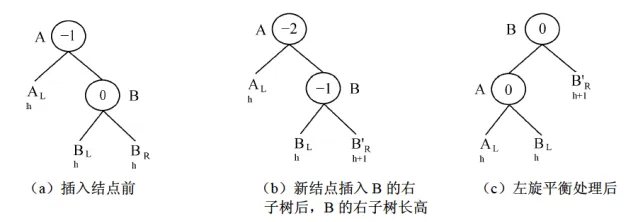
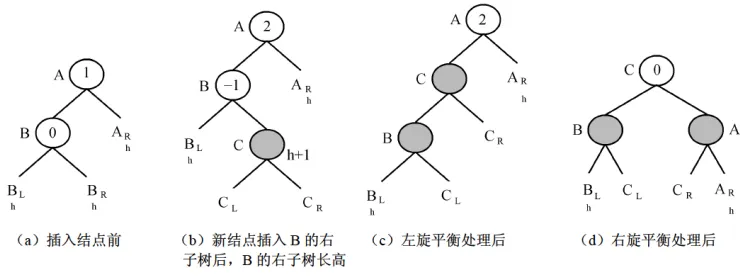
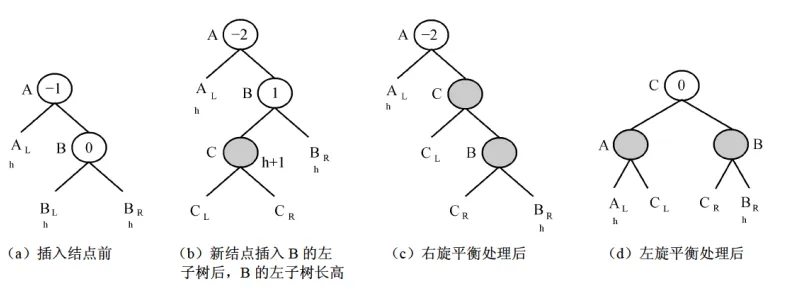
- 平衡调整:插入或删除破坏平衡后,需要通过来调整。分为四种基本类型:
- LL型()
- RR型()
- LR型()
- RL型()
- LL型()
- 性能指标:
- 时间复杂度:查找效率为 。
- 空间复杂度:。
- 稳定性:。旋转操作会完全改变树的结构和节点的相对位置。
- 特点:
- 解决了BST可能退化的问题,但维护平衡(旋转操作)增加了插入和删除的开销。
- 是BST的优化版本。
3.3 B树和B+树(简介)
- B树:一种,用于磁盘等直接存取设备上的文件组织和数据库索引。
- 结点中多个。
- 叶子结点都在上。
- B+树:B树的变型,所有,并。非叶子结点仅起索引作用。更适合文件系统和数据库的。
四、散列表(哈希表)查找(计算式查找)
4.1 基本概念
- 散列函数:根据关键字
key,通过散列函数H(key)直接。 - 示例:
H(key) = key % 7。将关键字[5, 3, 8, 1, 12]存入表长m=7的散列表中。5%7=5-> 存入地址5。3%7=3-> 存入地址3。8%7=1-> 存入地址1。1%7=1-> 冲突!使用线性探测法H₁=(1+1)%7=2-> 存入地址2。- 查找
1:H(1)=1,比较发现地址1是8,不等于1,继续线性探测下一个地址2,找到1。 散列表:根据关键字直接进行访问的数据结构。它通过散列函数建立了关键字到存储地址的映射。
4.2 散列函数的构造方法(考点)
- 直接定址法:。简单、无冲突,但地址空间需与关键字大小一致。
- 除留余数法:。最常用。 通常取小于表长 的最大质数,以减少冲突。
- 数字分析法:取关键字的某些取值较均匀的数码位作为地址。
- 平方取中法:关键字平方后,取中间的几位作为散列地址。
4.3 处理冲突的方法(核心考点)
- 开放地址法:开放地址法是在哈希表的线性存储空间内,当发生冲突时,通过特定的探测规则存储数据。
- 核心公式为: ,其中 是原哈希函数, 是增量序列, 是哈希表长度。
- 线性探测法:,。容易产生“堆积”现象。
- 二次探测法:。,但。
- 链地址法(拉链法):链地址法(或拉链法)是一种经常使用且很有效的方法。它在查找表的每一个记录中,链域中存放下一个。 利用链域,就把若干个发生冲突的记录。当链域的值为 时,表示已没有后继记录了。因此,对于的。
- 优点:无堆积现象;动态申请结点,适用于的情况;。
- 再哈希:使用,当第一个函数冲突时,依次调用后续函数计算地址,。公式为
4.4 散列表的查找性能分析
- 决定因素:散列函数、处理冲突的方法、装填因子 α。
- 装填因子:。 越大,表越满,发生冲突的可能性越大。
- ASL:散列表的查找效率与表中元素个数 无关,只与装填因子 有关。 越小,冲突可能性越小,ASL越小。
五、总结与软考考点聚焦
| 查找技术 | 适用场景 | 平均时间复杂度 | 软考重点 |
|---|---|---|---|
| 顺序查找 | 无序线性表 | 算法简单,ASL计算 | |
| 折半查找 | 有序顺序表 | 手工模拟过程,画判定树,计算ASL | |
| 二叉排序树 | 动态查找表 | ~ | BST性质,删除操作,查找效率 |
| 平衡二叉树 | 动态查找表 | 平衡调整(四种旋转) | |
| 散列查找 | 快速访问 | 散列函数构造,处理冲突方法,ASL分析 |
备考建议:
- 必会手工模拟:二分查找的过程、BST的查找/插入/删除过程、AVL的旋转调整过程、散列表的构造和冲突解决过程。
- 掌握ASL计算:特别是二分查找判定树和散列表的ASL计算。
- 理解本质:理解各种查找技术的适用场景和优缺点,特别是BST、AVL、B树、哈希表之间的区别。