00:00:00
计算机系统组成 原创
一、 冯诺依曼机
冯·诺伊曼结构(von Neumann architecture),也称冯·诺伊曼模型(Von Neumann model)或普林斯顿结构(Princeton architecture),是一种将程序指令存储器和数据存储器合并在一起的计算机设计概念结构。 依据冯·诺伊曼结构设计出的计算机称做冯.诺依曼计算机,又称存储程序计算机。
1.1 冯诺依曼机特点
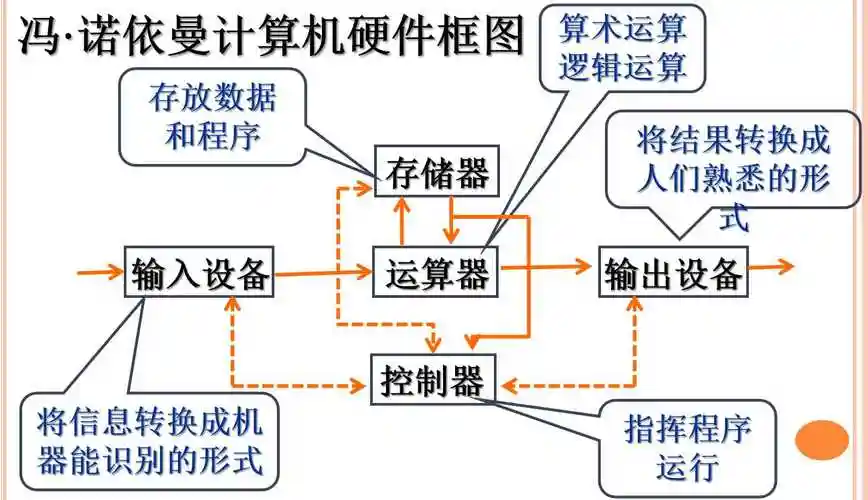
- 计算机由组成,分别是:运算器、控制器、存储器、输入设备和输出设备。
- 指令和数据以存于存储器中,可按照地址寻访
- 指定和数据使用二进制的形式表示
- 指令由操作码和地址码组成
结构图如下所示:
1.2 存储器(主存储器)
主存储器主要由三大部分组成
- 存储体(Storage Body / Memory Bank):数据的"仓库"
- 地址寄存器 () 和地址译码驱动电路:寻址的"导航系统"
- 数据寄存器 () 和读写电路:数据的“出入口和搬运工”
1.2.1 存储体
存储体中重要概念:存储元(Storage Element)、存储单元(Storage Unit)、存储字(Storage Word)、存储字长(Storage Word Length)
- 存储元 (Storage Element):是构成存储体的。例如,在DRAM芯片中,一个电容和一个晶体管共同构成一个存储元,
- 存储单元 (Storage Unit):是存储体中。它由。 现代计算机中,(即1字节)。
- 存储字 (Storage Word):是存储在一个存储单元里的。它是存储单元所存储的。
- 存储字长 (Storage Word Length):是存储体的一个设计特征,指每个。
1.2.2 数据寄存器(MDR)和地址寄存器(MAR)
它们是CPU与主存储器之间进行数据交互的。
| 寄存器 | 全称 | 功能 | 方向 | 连接的CPU总线 |
|---|---|---|---|---|
| MAR | Memory Address Register (地址寄存器) | 存放CPU要访问的。 | CPU → 主存 | 地址总线 (Address Bus) |
| MDR | Memory Data Register (数据寄存器) | 临时存放要从主存读出或写入的数据。 | CPU ↔ 主存 | 数据总线 (Data Bus) |
地址寄存器 (MAR - Memory Address Register)
功能:用于CPU通过地址总线发送过来的、想要访问的。
核心作用:
- 地址暂存与稳定:CPU发送地址信号的时间很短,而内存的寻址操作(译码、驱动)需要一定的时间。MAR的作用就是锁存并保持这个地址信号,为内存内部的地址译码器提供稳定的输入,确保整个读/写操作期间地址不会改变。
- 决定寻址范围:MAR的位数(宽度) 直接决定了主存储器最大的可寻址空间。
- 公式:
可寻址空间 = 2MAR位数 - 例如:如果MAR是32位的,那么它可以存储2³²个不同的地址,对应最大4GB(2³² Bytes)的寻址空间。如果MAR是64位的,寻址空间则大得惊人(2⁶⁴ Bytes)。
- 公式:
工作流程(以读数据为例)
- CPU想要读取地址为
0x1234的数据。 - CPU将地址
0x1234通过 地址总线 送入 MAR。 - MAR 锁存 并 输出 这个地址给内存内部的 地址译码器。
- 地址译码器开始工作,根据该地址找到对应的物理存储单元。
- CPU想要读取地址为
数据寄存器 (MDR - Memory Data Register)
功能与作用
- 功能:用于暂时存放CPU与主存储器之间待传输的数据。
- 核心作用:
- 数据缓冲与同步:作为CPU数据总线和存储器内部数据线之间的缓冲器。CPU和内存的工作速度可能不同步,MDR在其中起到速度匹配和数据暂存的作用,防止数据丢失。
- 双向数据传输:
- 读操作时:MDR存放从存储体中读出的数据,准备让CPU通过数据总线取走。
- 写操作时:MDR存放CPU通过数据总线送来的、准备要写入存储体的数据。
工作流程
- 读操作:
- 当地址译码器选中目标单元后,该单元的数据被读出。
- 读出的数据经过放大和整形,被送入MDR中暂存。
- MDR将数据放到数据总线上,CPU再从总线上读取该数据。
- 写操作:
- CPU将要写入的数据通过数据总线送入MDR。
- 同时,CPU将目标地址通过地址总线送入MAR(找到要写入的位置)。
- 内存控制逻辑将MDR中的数据写入到由MAR地址选中的存储单元中。
- 读操作:
重要说明与现代计算机架构
位置归属:在传统的描述中,MAR和MDR被视为的组成部分(即位于内存板上)。然而,在,成为CPU内存管理单元(MMU)或总线接口单元(BIU)的一部分。但它们的,依然是CPU和主存之间的地址和数据接口。
与字长的关系:
- 决定了系统的寻址能力(是32位还是64位系统)。
- MDR的位数通常与计算机的字长(Word Size)相关,但不一定相等。例如,一个64位CPU的MDR宽度可能是64位,这意味着它一次可以访问8个字节的数据(假设存储单元为8位)。但CPU仍然可以按字节、字、双字等方式来访问,底层硬件会进行转换。
1.3 运算器(Arithmetic Logic Unit, ALU)
用于执行(加、减、乘、除等)和(与、或、非等),是处理的。
1.3.1 核心部件
- 核心部件总览
| 缩写 | 英文全称 | 中文名称 | 核心功能 |
|---|---|---|---|
| ACC | Accumulator | 累加寄存器 | 存放 或 |
| MQ | Multiplier-Quotient Register | 乘商寄存器 | 在乘除运算中存放 或 |
| X | (General-purpose) Operand Register | 操作数寄存器 | 存放一个 |
| ALU | Arithmetic Logic Unit | 算术逻辑单元 | 执行实际的 |
| DR | Data Register | 数据寄存器 | 作为内存和运算器之间的 |
| PSW | Program Status Word | 程序状态字 | 存放运算结果的 |
- 运算过程中的协作关系,尤其是ACC、MQ、X在乘法运算中的典型数据流:
各部件详细说明
- (Accumulator)
- 功能:这是运算器中的寄存器之一。它主要用于存放被操作数和运算结果。
- 工作方式: * 在许多指令中,一个操作数默认来自ACC。 * ALU的运算结果也通常会, hence the name "累加" (Accumulate)。
- 示例:执行
ADD B指令,意味着(ACC) + (B) -> ACC,将ACC中的值与B单元的值相加,结果存回ACC。
- (Multiplier-Quotient Register) -
- 功能:这是一个,主要用于操作。
- 工作方式:
乘法时:存放。运算结束后,存放结果的部分(乘积可能很长,是操作数位数的两倍)。
除法时:存放。除法运算后,。 - 示例:早期乘法指令
MUL X,可能意味着(ACC) × (MQ) -> ACC-MQ,将ACC和MQ中的数相乘,。
- (Operand Register)
- 功能:这是一个。
- 工作方式:用于另一个操作数。当需要从读取数据参与运算时,数据通常寄存器,然后再由ALU与ACC中的数据进行运算。
- 示例:执行
SUB [1000H]指令,操作是:
1. 将内存地址1000H处的数据取到 X 寄存器。
2. ALU执行(ACC) - (X)操作。
3. 结果送。
- (Arithmetic Logic Unit)
- 功能:这是运算器的,是一个由组合逻辑电路(如加法器、移位器、逻辑门等)构成的部件,。
- 工作方式:它从ACC、X、MQ等,根据控制单元(CU)发出的命令执行(加、减、乘、除)或逻辑运算(与、或、非、异或),然后将到目标寄存器(如ACC、MQ),并。
- (Data Register)
- 功能:也称为MDR(Memory Data Register),它是。
- 工作方式:
- 读内存:从内存读出的数据,首先被送入DR,然后再被移动到运算器所需的寄存器(如X、ACC)中。
- 写内存:要写入内存的数据,也是先从运算器寄存器(如ACC)移动到DR,然后再从DR写入到指定内存地址。
- 目的:协调CPU的高速和内存的相对低速,完成速度匹配。
- (Program Status Word)
- 功能:这是一个按位定义的寄存器,每一位(或几位)代表一种,主要由ALU运算结果设置。
- 核心标志位:
- CF (Carry Flag):进位标志。无符号数运算产生进位或借位时置1。
- OF (Overflow Flag):溢出标志。有符号数运算结果超出表示范围时置1。
- ZF (Zero Flag):零标志。运算结果为0时置1。
- SF (Sign Flag):符号标志。运算结果为负时置1(即最高位为1)。
- PF (Parity Flag):奇偶标志。结果中1的个数为偶数时置1。
- (Accumulator)
协同工作示例:乘法运算 计算
5 * 3。初始化:
- 将被乘数
5放入 ACC。 - 将乘数
3放入 MQ。 - 控制器发出乘法操作命令。
- 将被乘数
执行运算:
- ALU 从ACC和MQ中取出操作数,执行乘法操作。
- 乘积
15是一个比原操作数更长的数。 - 结果的高位部分(本例中为
0)放回 ACC。 - 结果的低位部分(
15)放入 MQ。 - PSW 中的标志位根据结果
15被更新(例如ZF=0,SF=0,因为15非零且为正)。
结果:
- ACC-MQ 寄存器对共同构成了乘积结果。
1.4 控制器(Arithmetic Logic Unit, ALU)
控制器是计算机的“指挥中心”,它的作用是确保能够被。
控制器各核心部件在“取指-执行”周期中的工作流程与协作关系:
1.4.1 核心部件总览
| 缩写 | 英文全称 | 中文名称 | 核心功能 |
|---|---|---|---|
| CU | Control Unit | 控制单元 | 控制器的核心, 的部件 |
| IR | Instruction Register | 指令寄存器 | 存放的指令 |
| PC | Program Counter | 程序计数器 | 存放要执行的指令的 |
| AR | Address Register | 地址寄存器 | 存放当前要访问的内存地址 |
| ID | Instruction Decoder | 指令译码器 | IR中的指令,确定操作类型 |
1.4.2 各部件详细说明
- (Control Unit)
- 功能:这是控制器乃至整个CPU的和“神经中枢”。它本身,而是。
- 工作方式:
- 它根据 的输出(这是一条什么指令?)。
- 根据 (时钟脉冲)。
- 根据 (来自PSW的标志位,如进位、零标志等)。
- 产生一个特定的、具有固定时间顺序的。
- 示例:执行一条
ADD加法指令时,CU会按顺序产生以下控制信号:从取操作数 -> 将 -> 命令ALU做加法 -> 将 -> 更新状态寄存器等。。
- (Instruction Register)
- 功能:用于存放 的指令。
- 工作方式:
- 从内存中取出的指令,首先被送到
- 然后,该指令从被送入中
- 指令在IR中被分为两部分:
- 操作码(Opcode):送交进行。
- 地址码(Address):可能包含操作数的地址,可送交。
- 特点:指令在,确保CU执行的步骤是针对同一条指令。
- (Program Counter)
- 功能:也叫。它的内容是下一条要执行的指令在内存中的地址。
- 工作方式:
- 顺序执行:当一条指令被后,(或加上指令长度的字节数),指向指令的地址。
- 跳转/分支:当执行指令(如
JMP)、调用子程序(CALL)或发生中断时,PC会被装入目标地址,从而改变程序的执行流程。
- 重要性:PC保证了程序能够 执行下去,是实现“存储程序”概念的关键。
- (Address Register)
- 功能:用于存放。
- 工作方式:
- 无论是取指令还是存取数据,都需要。
- 这个地址可以来自PC(取指令时)、来自IR的地址码部分(取操作数时)或是运算结果。
- 该地址被放入,AR通过 将地址信号送到内存,内存根据该地址进行寻址。
- 作用:作为CPU地址总线的和,确保地址信号的稳定。
- (Instruction Decoder)
- 功能:一个,负责对IR中的。
- 工作方式:
- 它将二进制编码的操作码(如
10110110)作为输入。 - 通过内部逻辑电路,将其“翻译”成对应指令所需的。
- 译码结果输出给,告诉CU“现在要执行的是什么操作”(是加法?是比较?还是跳转?)。
- 它将二进制编码的操作码(如
- 类比:像一个翻译官,将二进制指令“翻译”成CU能理解的“命令意图”。CU再根据这个“意图”去组织具体的微操作步骤。
1.4.3 协同工作流程示例:执行一条指令
以执行一条简单指令 ADD [1000H] (将地址1000H中的数加到ACC中) 为例:
取指(Fetch):
- 将指令地址送给。
- 将地址送内存,内存取出指令,经送到。
- 自动加1,指向下一条指令。
- 开始译码IR中的操作码,发现是 `ADD` 指令,并通知。
执行(Execute):
- 根据ID的译码结果,开始发出微操作信号。
- 中的地址码部分(`1000H`)被送入。
- 将地址 `1000H` 送内存,内存找到该地址的数据,经读出。
- 控制将中的数据送入ALU的一个输入端,ACC中的数据送入另一个输入端。
- 命令ALU执行加法操作。
- 控制将ALU的结果写回,并更新状态位。
1.4.4 总结
这些部件精密协作,周而复始地,从而让计算机自动运行程序:
- PC 和 AR 负责。
- IR 和 ID 负责。
- CU 是总指挥,负责根据前者的信息。
1.5 冯诺依曼机小结
注意
- 在现代计算机中通常将
运算器和控制器集成在一块芯片上,称之为中央处理器,即CPU - 这五大部件通过系统总线(Bus) 相互连接,进行数据和指令的传输,共同构成了一个能够自动、高速处理信息的完整系统。
二、 Flynn 分类法
Flynn 分类法由 Michael J. Flynn 在 1966 年提出,是一种根据 和 的数量对计算机体系结构进行分类的经典方法。
- 指令流 (Instruction Stream):计算机执行的指令序列
- 数据流 (Data Stream):指令流所操作的数据序列
它通过识别计算机中多少条指令流和多少个数据流,将计算机划分为
2.1 四大类型计算机特点
- (Single Instruction, Single Data)
- 描述:这是最传统的架构。在任何时钟周期内,只有(CU)从内存中取出,并只对进行操作
- 关键特点:
- 典型代表:早期的
- 符合经典的
- (Single Instruction, Multiple Data)
- 描述:一条指令可以同时。(CU)控制,所有PU在同一时刻执行同一条指令,但操作的是
- 关键特点:
- 非常适合数据,即对执行的操作
- 典型代表:
- :Cray超级计算机
- 现代处理器中的:Intel 的 MMX, SSE, AVX 和 ARM 的 NEON。这些指令允许一条指令同时对多个数据(如4个float数)进行加法等操作
- (图形处理器):GPU的核心渲染理念就是SIMD,对大量像素或顶点执行相同的着色指令
- (Multiple Instruction, Single Data)
- 描述:执行的指令。这种架构非常罕见,几乎没有商业化的成功实践
- 关键特点:
- 可用于容错计算(多个PU对同一数据进行计算并投票表决结果)或异构计算(对同一数据流进行一系列不同的操作)
- 常被引用的唯一例子是冗余容错系统,多个独立计算的单元对相同输入进行计算以检查错误
- (Multiple Instruction, Multiple Data)
- 描述:这是目前、最通用的并行计算机架构。系统中有处理单元(PU),每个都有)。因此,每个PU可以,操作的数据
- 关键特点:
- 实现了和
- 处理器之间
- 典型代表:
- :你的双核、四核、八核CPU。每个核心都是一个独立的SISD处理单元,它们共同组成了一个MIMD系统
- :服务器上的多个CPU
- :通过网络连接的多台计算机
2.2 总结与对比
| 类型 | 指令流 | 数据流 | 特点 | 常见应用 |
|---|---|---|---|---|
| SISD | 单 | 单 | 串行执行 | 传统单核处理器 |
| SIMD | 单 | 多 | 向量计算、多媒体指令集 (SSE/AVX)、GPU | |
| MISD | 多 | 单 | ,极少应用 | 容错系统(学术研究), |
| MIMD | 多 | 多 | 多核处理器、分布式系统、计算机集群 |